5月28日上午,我校举行“冷门绝学”专业建设成果发布会,由我校中国文字研究与应用中心利用图像识别工具与数据库结合创建的“中国文字数字平台”已经取得重大成果,殷商甲骨文、商周金文、战国楚简等可搜集到的文字均已入库,目标是将中国历代出土的实物文字材料都纳入可以运用数字化来处理和研究的范围。
汉语古文字数据库
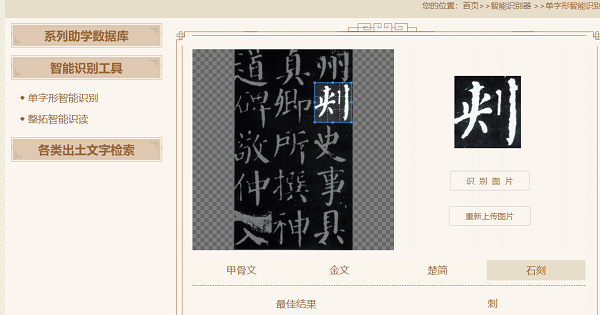
以往的技术仅能识别出某个出土文字图像属于今天哪个楷字的字目,却不能确认图像是哪个古文字材料中的哪个字。因为,历代出土实物文字材料的用字,大面积未被国际标准字符集覆盖,约7万个古文献用字存在网络使用障碍。而且,过去常见的文字数据库普遍存在集外字无法检索的问题。而建设“中国文字数字平台”,正是为了推动古文字图像识别走出“抽象识字”的局限。同时,该平台的建成还能消除已有的其他一些古文字数据库的盲点,可以实现数字平台中图片载体材料与字符集载体材料的自动数字关联,营造出古文字资料大数据生成和机器识读的环境。
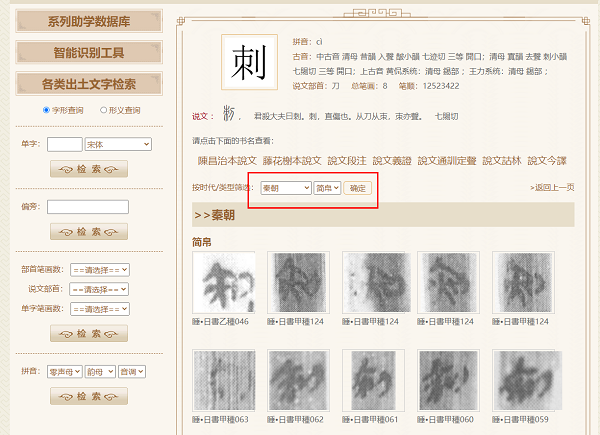
据我校中国文字研究与应用中心副主任刘志基 、计算中心高级工程师陈优广介绍,“中国文字数字平台”已被打造成智能型古汉语文字的数字平台,迄今为止,智能检索数据库所包含的文字材料,覆盖了自殷商到明清整个汉字发展史上各种时段、各种类型的文字。先秦部分基本囊括了目前已公布的文字资料,先秦以后部分则汇集了各时段代表性的文字资料。因此,该数字平台堪称电子版的“字海”,可以提供覆盖整个汉字发展史的相关文字信息的检索查询。此外,研究团队通过海量文献用字的逐一整理,还研发了完整的出土实物文字字符集标准体系,覆盖数据库使用所有字符的有效输入检索手段,这样就能保证库内所有字符与标准码位的一字一码精确对应,保证了数据库各种资料都处于有效的数字化处理范围之内。因此,“中国文字数字平台”上的智能检索数据库,也就成为目前世界上唯一可全字符(集外与集内字、楷字与原形字、整字与偏旁)检索的出土汉语文字数据库。
据悉,在目前的平台里,殷商甲骨文数据库有7万余片甲骨,110万字;商周金文数据库有1.7万篇器铭,18万字;战国楚简数据库有9种著录,10万字;先秦古玺、古陶、古币和石刻文字数据库有3.7万方,16万字;秦汉简牍数据库有50种简牍,90万字;汉代金石文字数据库有3万方金石,20万字;魏晋至元代石刻文数据库有1.5万种石刻,300万字;唐代写本文字数据库有500篇,60万字;元明刻本文字数据库有四种刻本,24万字;明清手写文字数据库有920片文字,7万字;中国古代字书数据库有6万字头,300多万字……
来源|新民晚报
编辑|石钰
审核|王曼
